



Next: 5.5.3 Parallel IUL factorization
Up: 5.5 Incomplete factorizations
Previous: 5.5.1 Sequential algorithm
Contents
5.5.2 Parallel ILU-Factorization
The first idea for parallelization of ILU is the simple
rewriting of Alg. 5.12 with an accumulated matrix
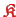 .
Naturally,
.
Naturally,
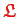 und
und
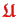 are also accumulated matrices, however,
because of (4.9) and (4.10) we have to fulfill
requirements on the mesh 3a and 3b
from Sec. 4.3.1.
are also accumulated matrices, however,
because of (4.9) and (4.10) we have to fulfill
requirements on the mesh 3a and 3b
from Sec. 4.3.1.
![\begin{algorithmus}
% latex2html id marker 20045
[H]
\caption{Parallelized $\pro...
...- P_{I} $\ &
DD $\rightarrow$\ block matrices
\end{tabular}
\end{algorithmus}](img599.gif)
The redundantly stored matrices
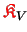 ,
,
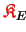 ,
,
,
,
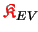 and
and
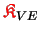 will not updated before their (pointwise) factorization so
that the matrix accumulation can be performed in the beginning.
will not updated before their (pointwise) factorization so
that the matrix accumulation can be performed in the beginning.
In 3D, additional blocks with subscript ''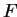 '' have to be taken into account.
The proper factorization is similar but some additional conditions on
the mesh appear.
'' have to be taken into account.
The proper factorization is similar but some additional conditions on
the mesh appear.
Comparing those
matrix-times-vector multiplications (4.9) and (4.10)
admissible for accumulated matrices within the elimination
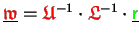 ,
one can derive that therein 3 vector type changes are necessary.
,
one can derive that therein 3 vector type changes are necessary.
![\begin{algorithmus}
% latex2html id marker 20194
[H]\caption{Parallel eliminatio...
...ne{{\ensuremath{\color{green}{\sf w}}}}_i$\ \\
\end{tabular}
\end{algorithmus}](img604.gif)
The diagonal matrix 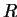 including the number of subdomains sharing a node
was defined in (4.4).
including the number of subdomains sharing a node
was defined in (4.4).
Improvement :
The disadvantage of Alg. 5.15 consists in the fact that
always the wrong vector type is available. This leads to the
3 vector type changes including 2 accumulations and means
doubling the communication costs per iteration compared to the
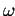 -Jacobi iteration.
-Jacobi iteration.
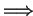 According to (4.12a), the elimination
According to (4.12a), the elimination
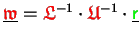 would require only one vector type change including one accumulation.
would require only one vector type change including one accumulation.
Next: 5.5.3 Parallel IUL factorization
Up: 5.5 Incomplete factorizations
Previous: 5.5.1 Sequential algorithm
Contents
Gundolf Haase
2000-03-20