



Next: 5.3 -Jacobi iteration
Up: 5.2 GMRES solver
Previous: 5.2.1 Sequential algorithm
Contents
5.2.2 Parallel GMRES
We have to distinguish in algorithm 5.3
not only between functionals
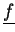 ,
,
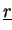 and state variables
and state variables
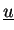 ,
,
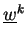 but also with
vectors
but also with
vectors
![$ \{z_i\}_{i=\overline{1,k+1} \makebox[0pt]{}}$](img512.gif) ,
,
![$ \{s_i\}_{i=\overline{1,k+1} \makebox[0pt]{}}$](img513.gif) ,
,
![$ \{c_i\}_{i=\overline{1,k+1} \makebox[0pt]{}}$](img514.gif) and matrix
and matrix
![$ \{h_{i,j}\}_{i,j=\overline{1,k} \makebox[0pt]{}}$](img515.gif) which do not fit in that scheme.
Therefore, we will handle them just as scalar values in the
parallelization.
which do not fit in that scheme.
Therefore, we will handle them just as scalar values in the
parallelization.
Our strategy for parallelization of the GMRES without
preconditioning (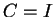 ) is the following.
) is the following.
- $&bull#bullet;$
-
,
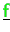 ,
,
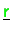 are
distributed stored.
are
distributed stored.
- $&bull#bullet;$
-
,
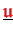 ,
,
 are
accumulated stored.
are
accumulated stored.
- $&bull#bullet;$
- Store the scalar values
,
,
and
redundantly on each processor.
-
- Inner products require only a minimum of
communication (4.7), matrix-times-vector operation
requires no communication at all (4.8).
- !!
- The setting
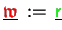 includes one
change of the vector type via accumulation (4.5).
Here we need communication between all the processes
sharing the proper data.
includes one
change of the vector type via accumulation (4.5).
Here we need communication between all the processes
sharing the proper data.
- $&bull#bullet;$
- All operations on scalar values
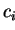 ,
, 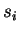 ,
, 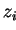 and
and 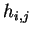 will be performed locally on each processor.
These operations are redundant.
will be performed locally on each processor.
These operations are redundant.
- !!
- Nearly all DAXPY-operations use the same vector types
(and scalar values) excluding the operation
combining different vector types.
Changing an accumulated vector
 into a distributed one
can be done without any communication (4.6) !
into a distributed one
can be done without any communication (4.6) !
-
- No DAXPY-operation requires communication.
![\begin{algorithmus}
% latex2html id marker 15107
[H]
\caption{Parallel GMRES} $ ...
...nderline{{\ensuremath{\color{red}\mathfrak{w}}}}^j
\end{array}$\end{algorithmus}](img524.gif)
The
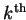 iteration of algorithm 5.4
includes
iteration of algorithm 5.4
includes 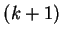 ALL/SMALL>_REDUCE-operations with one real number
and one vector accumulation.
Due to changing the type of vector
we have to perform
ALL/SMALL>_REDUCE-operations with one real number
and one vector accumulation.
Due to changing the type of vector
we have to perform
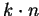 additional multiplications (
additional multiplications (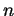 - length of vector
- length of vector
 ).
).
Parallelization of GMRES(m) with a restart after 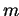 iterations
can be done in the same way as above.
iterations
can be done in the same way as above.
Next: 5.3 -Jacobi iteration
Up: 5.2 GMRES solver
Previous: 5.2.1 Sequential algorithm
Contents
Gundolf Haase
2000-03-20