



Next: 5.2 GMRES solver
Up: 5.1 CG method
Previous: 5.1.1 Sequential algorithm
Contents
5.1.2 Parallelized CG
Investigating the operations in the classical CG (Alg. 5.1 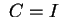 )
with respect to the results of section 4.3.1, we
achieve the following strategy for parallelization.
One objective therein is the minimization of communication steps.
)
with respect to the results of section 4.3.1, we
achieve the following strategy for parallelization.
One objective therein is the minimization of communication steps.
- $&bull#bullet;$
- Store matrix
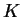 as distributed
as distributed
 (4.1).
Otherwise, we have to assume restrictions on the matrix pattern.
(4.1).
Otherwise, we have to assume restrictions on the matrix pattern.
-
- Vectors
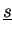 ,
,
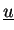
 ,
,
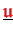 are accumulated (type-I) stored.
are accumulated (type-I) stored.
Matrix-times-vector results in a type-II
vector without any communication (4.8).
-
- Vectors
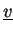 ,
,
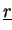 ,
,
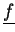
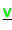 ,
,
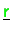 ,
,
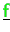 are distributed (type-II) stored and will never be
accumulated during the iteration.
are distributed (type-II) stored and will never be
accumulated during the iteration.
-
- If choosing additionally
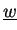
 as
accumulated vector then all DAXPY operations require no
communication at all.
as
accumulated vector then all DAXPY operations require no
communication at all.
- $&bull#bullet;$
- Due to the different types of the vectors used in the inner
products, those operations require only a very small amount
of communication (4.7).
- !!
- The setting
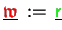 includes one
change of the vector type via accumulation (4.5).
Here we need communication between all the processes
sharing the proper data.
includes one
change of the vector type via accumulation (4.5).
Here we need communication between all the processes
sharing the proper data.
![\begin{algorithmus}
% latex2html id marker 14269
[H]
\caption{Parallelized CG} $...
...ad\sqrt{\sigma/\sigma_0}\,<\,
\mathrm{tolerance}}
\end{array}$\end{algorithmus}](img504.gif)
The resulting parallel CG algorithm 5.2
requires 2 ALL/SMALL>_REDUCE-operations with one real number
and one vector accumulation.
The same parallel algorithm can be achieved if one thinks of
the distributed stored vectors
,
and
in the sense of functionals
(or energy).
A mapping of the vectors onto functionals and state variables
seems to be a good attempt for parallelization.
Remark :
There exist versions of the CG bundling the two inner products
in a way that instead of two only one communication is needed.
This saves one startup time but the algorithm may run into
stability problems.
For the problem of preconditioning see section 5.8.
Next: 5.2 GMRES solver
Up: 5.1 CG method
Previous: 5.1.1 Sequential algorithm
Contents
Gundolf Haase
2000-03-20