



Next: 5.4 Gauß-Seidel iteration
Up: 5.3 -Jacobi iteration
Previous: 5.3.2 Data flow of
Contents
5.3.3 Parallel algorithm
We store usually the stiffness matrix 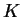 as distributed but we need
in the division by the entries of the main diagonal in
algorithm 5.5 the accumulated values of them.
Therefore, we have to store the main diagonal separately and
accumulate it.
The strategy for parallelization follows the parallelization
of the cg method in 5.1.2 .
as distributed but we need
in the division by the entries of the main diagonal in
algorithm 5.5 the accumulated values of them.
Therefore, we have to store the main diagonal separately and
accumulate it.
The strategy for parallelization follows the parallelization
of the cg method in 5.1.2 .
- $&bull#bullet;$
- Store the accumulated and inverted main diagonal as vector
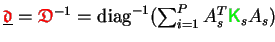 .
.
- $&bull#bullet;$
- Matrix is stored as accumulated (type-II)
matrix
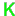 (4.1).
(4.1).
-
- Vector
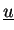
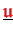 is accumulated (type-I),
vectors
is accumulated (type-I),
vectors
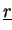 ,
,
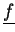
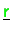 ,
,
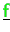 are distributed stored.
are distributed stored.
No communication in the matrix-times-vector
operation (4.8).
- !!
- Inner product requires different vector types
accumulation of
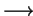
 .
.
- !!
- Using the accumulated vector
we can perform the remaining
DAXPY operations without any communication.
![\begin{algorithmus}
% latex2html id marker 16082
[H]\caption{Parallel Jacobi ite...
... \\
\multicolumn{3}{l}{ \mbox{\textbf{\sf end}}}
\end{array}$\end{algorithmus}](img533.gif)
Here, we denote by
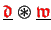 the component-wise multiplication
of two vectors, i.e,
the component-wise multiplication
of two vectors, i.e,
![$ \{{\ensuremath{\color{red}\mathfrak{d}}}_i \cdot {\ensuremath{\color{red}\mathfrak{w}}}_i\}_{i=\overline{1,n} \makebox[0pt]{}}\enspace$](img535.gif) .
This is nothing else then a multiplication of a vector by a
diagonal matrix.
If the relaxation parameter
.
This is nothing else then a multiplication of a vector by a
diagonal matrix.
If the relaxation parameter 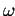 remains constant during
the iterations (
remains constant during
the iterations (
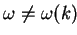 )
then the vector
)
then the vector
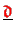 can be scaled with in the initial
step.
can be scaled with in the initial
step.
Each step of the Jacobi iteration requires one vector accumulation
and one ALL/SMALL>_REDUCE of a real number.
In case of using the Jacobi iteration as a smoother with a fixed
number of iterations the calculation of the inner product is
no longer necessary. This saves the ALL/SMALL>_REDUCE operation
in the parallel code
and vectors
and
can be stored in one place.
Next: 5.4 Gauß-Seidel iteration
Up: 5.3 -Jacobi iteration
Previous: 5.3.2 Data flow of
Contents
Gundolf Haase
2000-03-20