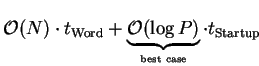| machine/OS |
latency |
bandwidth |
| Xplorer/Parix |
100  s s |
(meas.) 1.3 MB/sec |
| |
|
(peak) 8.8 MB/sec |
| T9000 |
10 s |
(est.) 80 MB/sec |
| Intel iPsc/860 |
82.5 s |
2.5 MB/sec |
| Convex SPP-1 |
0.2 s |
16.0 MB/sec |
| nCube2 |
|
71.0 MB/sec |
| Cray TT3D |
6 s |
120.0 MB/sec |
| IntelParagon |
|
200.0 MB/sec |
| Origin2000 |
|
(sust.) 680.0 MB/sec |
|