


Next: 5.3 Das -Jacobi Verfahren
Up: 5.2 Das GMRES-Verfahren
Previous: 5.2.1 Das serielle Verfahren
5.2.2 Der parallele GMRES
Bei Algorithmus 5.3 muß man neben den funktionalen Größen
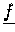 ,
,
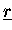 und den Funktionswerten
und den Funktionswerten
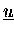 ,
,
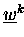 noch die
Vektoren
noch die
Vektoren
![$\{z_i\}_{i=\overline{1,k+1} \makebox[0pt]{}}$](img501.gif) ,
,
![$\{s_i\}_{i=\overline{1,k+1} \makebox[0pt]{}}$](img502.gif) ,
,
![$\{c_i\}_{i=\overline{1,k+1} \makebox[0pt]{}}$](img503.gif) und die Matrix
und die Matrix
![$\{h_{i,j}\}_{i,j=\overline{1,k} \makebox[0pt]{}}$](img504.gif) in Betracht ziehen, wobei diese innerhalb des Algorithmus als
skalare Größen betrachtet werden.
Folgende Parallelisierungsstrategie wird auf den
GMRES ohne Vorkonditionierung (
in Betracht ziehen, wobei diese innerhalb des Algorithmus als
skalare Größen betrachtet werden.
Folgende Parallelisierungsstrategie wird auf den
GMRES ohne Vorkonditionierung (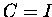 )
angewandt.
)
angewandt.
-
-
,
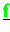 ,
,
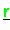 werden verteilt
gespeichert.
werden verteilt
gespeichert.
-
-
,
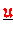 ,
,
 werden
akkumuliert gespeichert.
werden
akkumuliert gespeichert.
-
- Die skalaren Größen
,
,
und
werden
redundant auf jedem Prozessor lokal gespeichert.
-
- Skalarprodukte können mit sehr geringem
Kommunikationsaufwand ausgeführt werden (4.7).
Matrix-mal-Vektor benötigt keine Kommunikation (4.8).
- !!
- Die Zuweisung
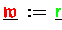 beinhaltet eine
Vektortypumwandlung mittels Akkumulation (4.5)
und damit eine Kommunikation über die zu mehreren Prozessen
gehörenden Daten.
beinhaltet eine
Vektortypumwandlung mittels Akkumulation (4.5)
und damit eine Kommunikation über die zu mehreren Prozessen
gehörenden Daten.
-
- Alle Manipulationen an und mit den skalaren Größen
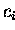 ,
,
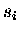 ,
,
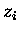 und
und 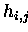 werden redundant auf allen Prozessoren lokal ausgeführt.
werden redundant auf allen Prozessoren lokal ausgeführt.
- !!
- Fast alle DAXPY-Operationen arbeiten mit den
gleichen Vektortypen (und skalaren Größen), außer
der Operation
welche verschieden Vektortypen enthält.
Eine Umwandlung des akkumulierten Vektors
 in einen
verteilten ist nach (4.6) aber ohne Kommunikation möglich !
in einen
verteilten ist nach (4.6) aber ohne Kommunikation möglich !
-
- Alle DAXPY-Operationen kommen ohne
Kommunikation aus.
![\begin{algorithmus}% latex2html id marker 15282
[H]
\caption{Paralleler GMRES} $...
...rline{{\ensuremath{\color{red} \mathfrak{w} } }}^j
\end{array}$\end{algorithmus}](img513.gif)
Der resultierende parallele GMRES-Algorithmus 5.4 erfordert
in der 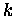 -ten Iteration (k+1) ALL/SMALL>_REDUCE-Operationen mit einer
reellen Zahl und eine Vektorakkumulation. Durch die notwendige Typumwandlung
des Vektors
kommen noch zusätzlich
-ten Iteration (k+1) ALL/SMALL>_REDUCE-Operationen mit einer
reellen Zahl und eine Vektorakkumulation. Durch die notwendige Typumwandlung
des Vektors
kommen noch zusätzlich 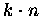 Multiplikationen
hinzu (
Multiplikationen
hinzu (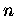 - Länge des Vektors
- Länge des Vektors
 ).
).
Die Variante GMRES(m), mit Neustart nach 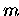 Iterationen, läßt sich
völlig analog parallelisieren.
Iterationen, läßt sich
völlig analog parallelisieren.
Next: 5.3 Das -Jacobi Verfahren
Up: 5.2 Das GMRES-Verfahren
Previous: 5.2.1 Das serielle Verfahren
Gundolf Haase
1998-12-22