


Next: 5.2 Das GMRES-Verfahren
Up: 5.1 Das CG-Verfahren
Previous: 5.1.1 Das serielle Verfahren
5.1.2 Der parallelisierte CG
Wählt man in Algorithmus 5.1 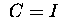 erhält man den klassischen CG.
Betrachtet man die darin enthaltenen Operationen und vergleicht sie
mit den Ausführungen in Abschnitt 4.3.1,
so kann man folgende Parallelisierungsstrategie aufbauen, wobei
die Anzahl der notwendigen Kommunikationen möglichst klein gehalten
werden soll.
erhält man den klassischen CG.
Betrachtet man die darin enthaltenen Operationen und vergleicht sie
mit den Ausführungen in Abschnitt 4.3.1,
so kann man folgende Parallelisierungsstrategie aufbauen, wobei
die Anzahl der notwendigen Kommunikationen möglichst klein gehalten
werden soll.
-
- Die Matrix
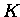 muß als
muß als
 (4.1)
verteilt (Typ-II) gespeichert werden, da im
anderen Fall Einschränkungen
an die Matrixstruktur erfolgen müssen.
(4.1)
verteilt (Typ-II) gespeichert werden, da im
anderen Fall Einschränkungen
an die Matrixstruktur erfolgen müssen.
-
- Vektoren
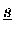 ,
,
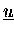
 ,
,
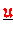 sind akkumuliert (Typ-I)
sind akkumuliert (Typ-I)
Matrix-mal-Vektor liefert Typ-II Vektor, ohne
daß Kommunikation notwendig ist (4.8).
-
- Vektoren
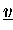 ,
,
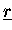 ,
,
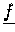
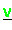 ,
,
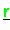 ,
,
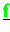 sind verteilt gespeichert (Typ-II) und werden im Verlauf der
Iteration nicht akkumuliert.
sind verteilt gespeichert (Typ-II) und werden im Verlauf der
Iteration nicht akkumuliert.
-
- Wählt man auch
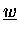
 akkumuliert, so lassen sich alle DAXPY-Operationen
ohne Kommunikation durchführen.
akkumuliert, so lassen sich alle DAXPY-Operationen
ohne Kommunikation durchführen.
-
- Da in den beiden Skalarprodukte der CG-Schleife unterschiedliche
Vektortypen verwendet werden, können diese Operationen
mit sehr geringem
Kommunikationsaufwand ausgeführt werden (4.7).
- !!
- Die Zuweisung
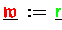 beinhaltet eine
Vektortypumwandlung mittels Akkumulation (4.5)
und damit eine Kommunikation über die zu mehreren Prozessen
gehörenden Daten.
beinhaltet eine
Vektortypumwandlung mittels Akkumulation (4.5)
und damit eine Kommunikation über die zu mehreren Prozessen
gehörenden Daten.
![\begin{algorithmus}% latex2html id marker 14445
[H]
\caption{Parallelisierter CG...
...m}\sqrt{\sigma/\sigma_0}\,<\,
\mathrm{tolerance}}
\end{array}$\end{algorithmus}](img494.gif)
Der resultierende parallele CG-Algorithmus 5.2 erfordert
pro Iteration 2 ALL/SMALL>_REDUCE-Operationen mit einer reellen Zahl
und eine Vektorakkumulation.
Man kann auch über andere Ansätze zu
Algorithmus 5.2 gelangen, so sind z.B. die verteilt gespeicherten
Vektoren
,
und
identisch mit den
funktionalen Größen im CG-Algorithmus (``Energie``). Eine Einteilung
der Vektoren in funktionale Größen und Funktionswerte liefert einen
guten Ansatz für die Zuordnung der 2 Vektortypen.
Bemerkung :
Es gibt cg-Varianten, in denen beide Skalarprodukte und damit die
entsprechende Kommunikationen zusammengefaßt werden können.
Dadurch spart man eine Startup-Zeit ein. Jedoch sind diese Varianten
unter Umständen instabil.
Zur Vorkonditionierungsproblematik siehe Abschnitt 5.8.
Next: 5.2 Das GMRES-Verfahren
Up: 5.1 Das CG-Verfahren
Previous: 5.1.1 Das serielle Verfahren
Gundolf Haase
1998-12-22