In 1966, Michael Flynn [Fly66] differentiated parallel
computer architectures with respect to data stream and instruction stream.
Table 2.1:
Classification by Flynn (Flynn's taxonomy)
Single
Multiple
Instruction Stream
SISD
MISD
Single
Data
SIMD
MIMD
Multiple
Stream
SISD :
Classical architecture
Parallelism is used only internally (bitwise parallel,
instruction scheduling, look ahead).
Pseudo parallelism by means of time sharing and multitasking
(Throughput of workstation will be improved).
SIMD :
Parallelism at instruction level
Data are distributed on the processes and one program
will be executed in equal steps.
Often quite simple processors are used but in a large amount
(processor arrays), e.g.: CM2, MasPar.
A typical problem on those computers consists in the
efficient handling of alternatives in the code :
In difference to a sequential computer,
a vector unit uses pipelining such that
the same sequence of instructions will be repeated on data sets.
A typical operation is the SAXPY-routine
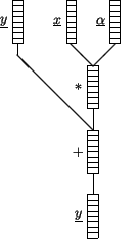
,
see Fig. 2.1 where
a vector
will be scaled by a scalar and added to
a
.
Here, the pipelining consists in loading operands,
multiplication, addition and storing of the result. All these
operations will be executed on special vector registers.
After a startup phase, the vector unit produces one component of
the result per clock although the sequential/scalar
execution would require
much more clocks.
Figure 2.1:
SAXPY in a vector unit
For achieving the full performance of the vector unit all
vector registers have to be filled all the time.
If this feeding of the vector registers stops then the
vector unit works just as a scalar unit and therefore
the performance drops by a factor of 50-200.
The additional vector
appearing in Fig. 2.1
is just a filling of the vector pipe with the constant scalar .
This will be done automatically by the compiler to handle
efficiently.
From the point of a mathematician, writing a code for a vector unit
is ''only'' sequential programming without any parallelism inside.
MIMD :
This is parallelism at the level of program execution, i.e.,
each processor runs its own code. Usually, those codes
do not run fully independent so that we have to distinguish between :
competitive processes (shared resources)
communicating processes (data stream, data exchange)
Differentiate between
Program (static) :
Exact notation of an algorithm.
Process (dynamic) :
Sequence of actions with only one assumption:
a positive program speed
Quite often, each process runs the same code on different data sets.
Class SPMD is a sub-class of MIMD
SPMD :
Single Program Multiple Data
Nowadays, this is the main class used in parallel programming
especially if a large number of processors is used.
Inherent data parallelism must be fulfilled.
There is no need for a synchron execution of the codes
at instruction level, thus a SMPD machine is
not a SIMD machine.
On the other hand there are synchronization points in the code
to update a few data.
![\begin{figure}\begin{center}
\unitlength0.05\textwidth
\begin{picture}(8,6)
\...
...b]{yes}} \put(6,4.2){\makebox(0,0)[b]{no}}
\end{picture}\end{center}\end{figure}](img40.gif)
![\begin{figure}[H]
\begin{minipage}[t]{0.45\textwidth}
If the test ''?'' result...
...} \put(9.2,0.5){\makebox(0,0)[l]{t}}
\end{picture}
\end{minipage} \end{figure}](img41.gif)
![\unitlength0.03\textwidth
\mbox{}\hfill
%% begin\{picture\}(5,12)
% Box [-1,1]x[...
...(Theorem of conservation of difficulties)
\end{minipage}\hfill\mbox{}\ [1ex]
%](img50.gif)