



Next: 2.2 Topologies
Up: 2.1 Classifications
Previous: 2.1.3 Classification by Flynn
Contents
2.1.4 Classification by memory access
Shared Memory (competitive processes) :
This is memory which will be accessed by several processes
''at the same time'', i.e,
they have to share that memory.
- Each process has access on all data.
 A sequential code can be easily ported to
parallel machines with that memory model and
leads usually with a small number of processors (
A sequential code can be easily ported to
parallel machines with that memory model and
leads usually with a small number of processors (
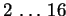 )
to a first increase in performance.
)
to a first increase in performance.

- If the number of processors increases then the number of
memory bank conflicts and other access conflicts rises.
Thus, the scalability cannot be guaranteed
(i.e., performance
 number of processors).
number of processors).
- For the decrease of access conflicts very efficient access administrations
and bus systems
are necessary.
system becomes more expensive.
There exists 3 different models how to realize
shared memory [Hwa93].
The UMA Model :
In the Uniform Memory Accesss Model,
all processors have equal access time to the whole memory which is
uniformely shared by all processors.
The NUMA Model :
In the Non-Uniform Memory Accesss Model,
the access time to the shared memory varies whith the
location of the processor.
The COMA Model :
In the Cache Only Memory Accesss Model,
all processors use only their local cache memory so that this memory model is
a special case of the NUMA model.
The KSR-1 and KSR-2 by Kendall Square Research had such a memory model.
Distributed Memory (communicating processes) :
This memory is a collection of memory pieces where each of them can be
accessed by only one process.
If a process requires data stored in the memory of another process then
communication between these processes is necessary.
- No access conflicts between processes (data are stored locally).
- Relatively inexpensive hardware
(but the most recent processors are also expensive)
- Nearly optimal scalable.
- No direct access on data stored on other processes.
Communication via special channels (links)
is necessary.
A sequential code would not run - special
parallel algorithms are required.
- $&bull#bullet;$
- The time needed for communication was underestimated 20 years
before. Nowadays, the ratio between arithmetic work and communication
is one criteria for the quality of a parallel algorithm.
- $&bull#bullet;$
- Bandwidth and transfer rate of the network between processors
is of great importance.
Distributed Shared Memory (DSM) :
(also known as Virtual Shared Memory)
This memory model is the attempt of a compromise between
shared und distributed memory.
The distributed memory has been combined with an OS-based
message passing system (see page ![[*]](file:/usr/local/lib/latex2html/icons/crossref.gif) )
which simulates the presence of a global shared memory, e.g.,
KSR: ''Sea of addresses'' and SGI: ''Interconnection fabric''.
)
which simulates the presence of a global shared memory, e.g.,
KSR: ''Sea of addresses'' and SGI: ''Interconnection fabric''.
- A sequential code will run immediately on that memory model.
If the algorithms take advantage of the local properties of data
(i.e., most data accesses of a process can be served from its own
local memory)
then a good scalability will be achieved.
Starting in spring 97,
SGI
delivers the parallel machine
Origin2000
with a
Scalable Symmetric Multiprocessing
(S2MP)2.1.
Each process (or a small group of processes) possesses its own local
memory but the parallel machine handles the whole memory as one
huge shared memory.
The realization was possible because of the very fast crossbar switch
(CrayLink) by Cray
(since 1996 subsidiary of SGI).
Remark :
In the context of the
EUROPORT
project from 1995-1997, 38 industrial application codes were ported
to parallel computers.
There are interesting comparisons
with respect to parallelization opportunities on several
programming models and parallel machines available.
From special interest is the fact, that preserving
in a shared memory code on a distributed shared memory machine
the local properties of the data (distributed memory model)
increases the performance of that code in comparison to a code
produced by a compiler with automatic parallelization.
The gap between both strategies gets bigger with increasing number of
processors.
Next: 2.2 Topologies
Up: 2.1 Classifications
Previous: 2.1.3 Classification by Flynn
Contents
Gundolf Haase
2000-03-20