|
Rewrite operation
|
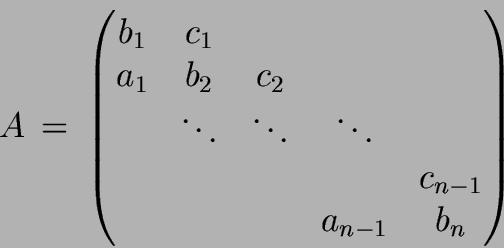
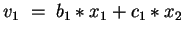
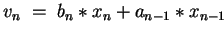
DO
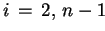
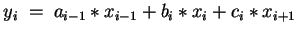
END DO
Code b) In comparison to code a), we enlarge vectors
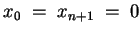
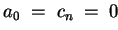
DO
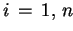
END DO
The first two lines in code a) have to be performed sequentially,
this results in a significant deceleration on a vector unit.
As a consequence, code b) ist faster
although slightly more operations have to be performed.