



Next: 4.1.3 Matrix-by-Matrix-operations (BLAS3)
Up: 4.1.2 Matrix-by-Vector operations (BLAS2)
Previous: 4.1.2 Matrix-by-Vector operations (BLAS2)
Contents
We want to perform
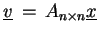 with a full matrix
with a full matrix  .
Depending on the distribution of the matrix we have various implementation
opportunities on a parallel machine
- two of them are investigated in the following.
.
Depending on the distribution of the matrix we have various implementation
opportunities on a parallel machine
- two of them are investigated in the following.
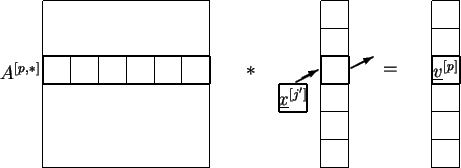
Variant 1 : Split into adjoint blocks of rows and distribute
them on the processors. The appropriate subvectors are handled similar.
Figure 4.2:
Matrix distributed as block rows
 |
![\begin{algorithmus}
% latex2html id marker 8367
[H]
\caption{Parallel Matrix-by-...
...{x} $\ and ''its''
initial subvector~$\underline{x}^{[p]}$.
\end{algorithmus}](img322.gif)
Variant 1 :
If ALL/SMALL>_TO/SMALL>_ALL/SMALL>_SCATTER-call distributes
 to all
processes in the beginning, then no communication is required in the
remaining operation.
to all
processes in the beginning, then no communication is required in the
remaining operation.
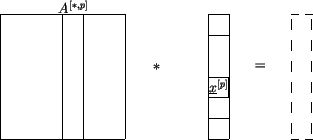
Variant 2 :
Split into adjoint blocks of columns and distribute
them on the processors. In the same way the appropriate subvectors of
are handled.
Figure 4.3:
Matrix distributed as block columns
 |
![\begin{algorithmus}
% latex2html id marker 8435\caption{Parallel Matrix-by-Vec...
...ach process~$p$\ owns the whole vector~$\underline{v}^{[p]}$.
\end{algorithmus}](img324.gif)
Applying the Broadcast-Multiply-Roll algorithm (Alg. 4.4)
from the next section on the Matrix-by-Vector operation leads
to an additional algorithm.
Next: 4.1.3 Matrix-by-Matrix-operations (BLAS3)
Up: 4.1.2 Matrix-by-Vector operations (BLAS2)
Previous: 4.1.2 Matrix-by-Vector operations (BLAS2)
Contents
Gundolf Haase
2000-03-20