



Next: 4.1.2 Matrix-by-Vector operations (BLAS2)
Up: 4.1.1 Vector-by-Vector operations (BLAS1)
Previous: 4.1.1.1 Determining the inner
Contents
We split vectors
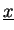 ,
,
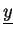 into
into 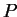 disjoint
subvectors of lengths
disjoint
subvectors of lengths 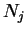 (
(
![$ \scriptstyle j=\overline{1,P} \makebox[0pt]{}$](img287.gif) ) and
store each of them on the appropriate processor
) and
store each of them on the appropriate processor 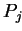 .
.
DO IN PARALLEL
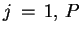
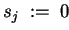
DO
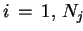
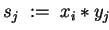
END DO
END DO
CALL ALL/SMALL>_REDUCE(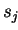 )
)
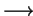
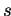 ,i.e.
,i.e.
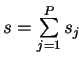
Exercise 11:
Write a small program which calculates the global inner product
of two disjoint stored vectors on a distributed memory machine.
|
Remark :
If one wants to create his own vector library
including BLAS1-routines as a subset, then the following two points are
advisable.
1
 level of implementation :
level of implementation :
A common tool for accelerating code is the loop unrolling, wherein
the ratio between arithmetics/load/store operations and the loop overhead
will be improved.
Let us investigate an inner product with stride 1.
![\fbox{\begin{minipage}[t]{0.3\textwidth}
$s \;=\; 0$ \\
DO $i = 1, N$ \\
\hspace*{3em} $ s\;=\;s + x_i \ast y_i $ \\
END DO
\end{minipage}}](img295.gif)
![\fbox{\begin{minipage}[t]{0.5\textwidth}
$m \;=\; N \mbox{mod} 4$ \\
$s \...
...m} + x_{i+2} \ast y_{i+2} + x_{i+3} \ast y_{i+3} $ \\
END DO
\end{minipage}}](img296.gif)
The best choice for the modulo (in example 4) is strongly hardware dependent
(number of pipes
 software pipelining, caches).
software pipelining, caches).
2
 level of implementation :
level of implementation :
Use same techniques as in the previous point but use BLAS1-routines
whenever possible, i.e.,
VDPLUS(
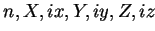 ), d.h.
), d.h.
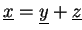 .
.
IF (adr(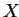 )==adr(
)==adr(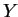 ) AND
) AND 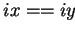 )
)
THEN CALL DAXPY(
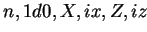 )
)
ELSE IF (adr()==adr(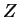 ) AND
) AND 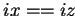 )
)
THEN CALL DAXPY(
)
ELSE Loop unrolling as in 1
level
END IF
END IF
Next: 4.1.2 Matrix-by-Vector operations (BLAS2)
Up: 4.1.1 Vector-by-Vector operations (BLAS1)
Previous: 4.1.1.1 Determining the inner
Contents
Gundolf Haase
2000-03-20