


Next: 5.4 Das Gauß-Seidel Verfahren
Up: 5.3 Das -Jacobi Verfahren
Previous: 5.3.2 Datengraph der Jacobi-Iteration
5.3.3 Das parallele Verfahren
Auch im parallelen Fall benötigt das 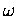 -Jacobi Verfahren
die Hauptdiagonalelemente der assemblierten Steifigkeitsmatrix.
Da diese verteilt gespeichert sind, muß die Hauptdiagonale
separat assembliert und gespeichert werden.
Die Parallelisierungsstrategie ähnelt dem Vorgehen beim
CG-Verfahren in Abschnitt 5.1.2 .
-Jacobi Verfahren
die Hauptdiagonalelemente der assemblierten Steifigkeitsmatrix.
Da diese verteilt gespeichert sind, muß die Hauptdiagonale
separat assembliert und gespeichert werden.
Die Parallelisierungsstrategie ähnelt dem Vorgehen beim
CG-Verfahren in Abschnitt 5.1.2 .
-
- Die invertierte assemblierte Diagonale wird als Vektor abgespeichert
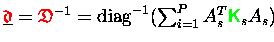 .
.
-
- Die Matrix
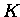 ist als
ist als
 (4.1)
verteilt (Typ-II) gespeichert.
(4.1)
verteilt (Typ-II) gespeichert.
-
- Vektor
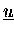
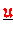 ist akkumuliert (Typ-I),
Vektoren
ist akkumuliert (Typ-I),
Vektoren
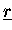 ,
,
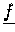
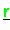 ,
,
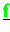 sind verteilt gespeichert.
sind verteilt gespeichert.
Matrix-mal-Vektor benötigt keine
Kommunikation (4.8).
- !!
- Das Skalarprodukt benötigt unterschiedliche Vektortypen
Akkumulation von
 .
.
- !!
- Mit dem akkumulierten Vektor
läßt sich nunmehr
die verbliebene DAXPY-Operation kommunikationsfrei ausführen.
![\begin{algorithmus}% latex2html id marker 16251
[H]\caption{Parallele Jacobi-Ite...
... \\
\multicolumn{3}{l}{ \mbox{\textbf{\sf end}}}
\end{array}$\end{algorithmus}](img520.gif)
Die in Algorithmus 5.6 vorkommende Operation
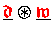 bezeichnet die komponentenweise Multiplikation
zweier Vektoren, d.h.
bezeichnet die komponentenweise Multiplikation
zweier Vektoren, d.h.
![$\{{\ensuremath{\color{red} \mathfrak{d} } }_i \cdot {\ensuremath{\color{red} \mathfrak{w} } }_i\}_{i=\overline{1,n} \makebox[0pt]{}}\enspace$](img522.gif) ,
und ist nichts anderes als
die Multiplikation einer Diagonalmatrix mit einem Vektor.
Falls der Relaxationsparameter
im Verlaufe der Iteration
konstant bleibt, kann man ihn
im Vorbereitungsschritt in den Vektor
,
und ist nichts anderes als
die Multiplikation einer Diagonalmatrix mit einem Vektor.
Falls der Relaxationsparameter
im Verlaufe der Iteration
konstant bleibt, kann man ihn
im Vorbereitungsschritt in den Vektor
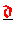 multiplizieren.
multiplizieren.
Falls kein Abbruchtest nötig ist, z.B. bei Verwendung als Glätter mit
einer fixen Anzahl von Schritten, dann kann man die Berechnung der
Skalarprodukte weglassen und
kann identisch
gewählt werden.
Per Jacobi-Iterationsschritt tritt somit eine Vektorakkumulation
und ein ALL/SMALL>_REDUCE einer reellen Zahl auf.
Next: 5.4 Das Gauß-Seidel Verfahren
Up: 5.3 Das -Jacobi Verfahren
Previous: 5.3.2 Datengraph der Jacobi-Iteration
Gundolf Haase
1998-12-22