


Next: 4.1.2.1 Parallelrechner mit verteiltem
Up: 4.1 Die BLAS-Bibliotheken
Previous: 4.1.1.2 Berechnung des Skalarproduktes
In diesem Abschnitt werden nur vollbesetzte Matrizen, bzw.
Matrizen mit Bandstruktur betrachtet.
Arten der Matrixspeicherung bei vollbesetzter Matrix 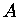 .
.
- 1.
- zeilenweise (row storage) [C,Pascal]
- 2.
- spaltenweise (column storage) [F77]
- 3.
-
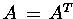 : zeilenweise oberes Dreieck
: zeilenweise oberes Dreieck 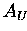
- 4.
-
: spaltenweise unteres Dreieck
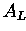
Aufgabe :
Stellen Sie die Operation
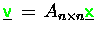 mittels
BLAS-Routinen ( DDOT, DAXPY) für die Speicherformen
i)-iii) dar.
mittels
BLAS-Routinen ( DDOT, DAXPY) für die Speicherformen
i)-iii) dar.
 Fall ii) ohne BLAS aber mit loop unrolling (Stride 2).
Fall ii) ohne BLAS aber mit loop unrolling (Stride 2).
Für die tridiagonale Matrix
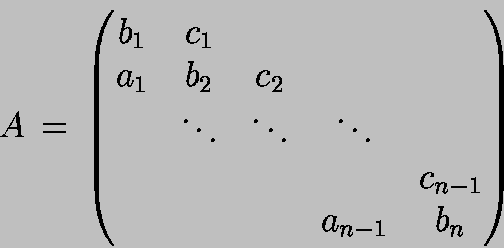
betrachten wir 2 Varianten der Matrix-Vektor Multiplikation
auf dem Vektorrechner.
Variante a) Die Matrix wird in den Vektoren
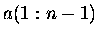 ,
,
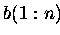 ,
,
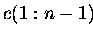 gespeichert.
gespeichert.
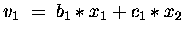
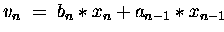
DO 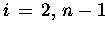
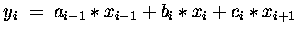
END DO
Variante b) Gegenüber Variante a) werden die
Vektoren 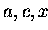 verlängert :
verlängert :
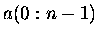 ,
,
,
,
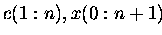 .
.
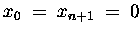
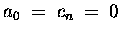
DO 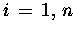
END DO
In Variante a) müssen die ersten beiden Zeilen seriell abgearbeitet werden,
was bei Vektorrechnern eine Geschwindigkeitseinbuße um das 5- 15-fache
bedeutet. Daher ist Variante b) auf dem Vektorrechner schneller, obwohl
mehr arithmetische Operationen ausgeführt werden müssen.
Next: 4.1.2.1 Parallelrechner mit verteiltem
Up: 4.1 Die BLAS-Bibliotheken
Previous: 4.1.1.2 Berechnung des Skalarproduktes
Gundolf Haase
1998-12-22