


Next: 4.1.2 Matrix-Vektor Operationen (BLAS2)
Up: 4.1.1 Vektor-Vektor Operationen (BLAS1)
Previous: 4.1.1.1 Berechnung des Skalarproduktes
Seien die Vektoren
 ,
,
 disjunkt in jeweils
disjunkt in jeweils 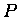 Teilvektoren
der Längen
Teilvektoren
der Längen 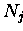 (
(
![$\scriptstyle j=\overline{1,P} \makebox[0pt]{}$](img284.gif) )
geteilt und auf dem entsprechenden
Prozessor
)
geteilt und auf dem entsprechenden
Prozessor 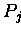 verfügbar.
verfügbar.
DO IN PARALLEL 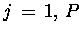
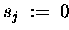
DO 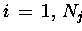
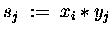
END DO
END DO
CALL ALL/SMALL>_REDUCE(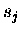 )
)
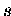 ,d.h.
,d.h. 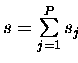
Aufgabe :
Programmieren Sie das globale Skalarprodukt zweier disjunkt
verteilter Vektoren
auf einem Parallelrechner mit verteiltem Speicher.
Bemerkung :
Eigene Bibliothek libvbasmod.a, welche als Untermenge
BLAS1-Funktionalität enthält.
1. Realisierungsebene :
Hochsprache C, F77 und Loop unrolling, dh. das Verhältnis
Arithmetik zu Schleifenverwaltung wird verbessert. Betrachten
das Skalarprodukt mit Stride 1.
![\fbox{\begin{minipage}[t]{0.3\textwidth}
$s \;=\; 0$\space \\
DO $i\,=\,1,\,N...
...\\
\hspace*{3em} $ s\;=\;s + x_i \ast y_i $\space \\
END DO
\end{minipage}}](img292.gif)
![\fbox{\begin{minipage}[t]{0.5\textwidth}
$m \;=\; N \,\mbox{mod}\,4$\space \\
...
...x_{i+2} \ast y_{i+2} + x_{i+3} \ast y_{i+3} $\space \\
END DO
\end{minipage}}](img293.gif)
Die Wahl des Moduloparameters (hier 4) ist hardwareabhängig.
2. Realisierungsebene :
Wie 1. mit zusätzlicher Benutzung der BLAS1-Routinen wo
dies möglich ist (und die vorhandene BLAS-Bibliothek fehlerfrei ist),
z.B. VDPLUS(
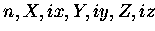 ), d.h.
), d.h.
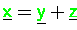
IF (adr(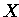 )==adr(
)==adr(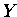 )
AND
)
AND 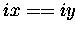 )
)
THEN CALL DAXPY(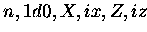 )
)
ELSE IF (adr()==adr(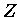 )
AND
)
AND 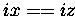 )
)
THEN CALL DAXPY()
ELSE Loop unrolling wie in 1. Realisierungsebene
END IF
END IF
Next: 4.1.2 Matrix-Vektor Operationen (BLAS2)
Up: 4.1.1 Vektor-Vektor Operationen (BLAS1)
Previous: 4.1.1.1 Berechnung des Skalarproduktes
Gundolf Haase
1998-12-22