


Next: 4.1.3 Matrix-Matrix-Operationen (BLAS3)
Up: 4.1.2 Matrix-Vektor Operationen (BLAS2)
Previous: 4.1.2 Matrix-Vektor Operationen (BLAS2)
Betrachten
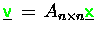 mit vollbesetzter
Matrix
mit vollbesetzter
Matrix 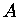 .
Je nach Aufteilung der Matrix unterscheidet sich
die programmtechnische Realisierung der Multiplikation auf dem
Parallelrechner. Zwei Varianten werden betrachtet.
.
Je nach Aufteilung der Matrix unterscheidet sich
die programmtechnische Realisierung der Multiplikation auf dem
Parallelrechner. Zwei Varianten werden betrachtet.
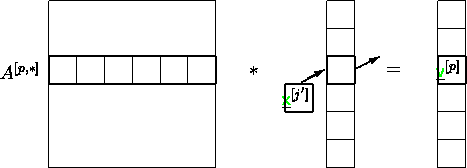
Variante 1 : Verteilen
blockzeilenweise auf die
Prozesse, analog die Teilvektoren.
Abbildung 4.2:
Matrix blockzeilenweise verteilt
 |
![\begin{algorithmus}% latex2html id marker 8229
[H]
\caption{Parallele Matrix-Vek...
...r~$\underline{{\ensuremath{\color{green} {\sf x}} }}^{[p]}$ .
\end{algorithmus}](img319.gif)
Variante 1b : Durch einen ALL/SMALL>_TO/SMALL>_ALL/SMALL>_SCATTER-Ruf
besitzt jeder Prozeß den gesamten Vektor
 .
Danach läßt sich
die Multiplikation ohne weitere Kommunikation ausführen.
.
Danach läßt sich
die Multiplikation ohne weitere Kommunikation ausführen.
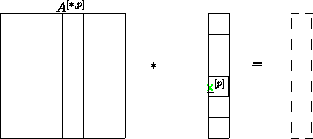
Variante 2 : Verteilen
blockspaltenweise auf die
Prozesse, Vektor
entsprechend der Spalten von .
Abbildung 4.3:
Matrix blockspaltenweise verteilt
 |
![\begin{algorithmus}% latex2html id marker 8305
\caption{Parallele Matrix-Vektor ...
...r~$\underline{{\ensuremath{\color{green} {\sf v}} }}^{[p]}$ .
\end{algorithmus}](img322.gif)
Ein weiterer Matrix-Vektor Algorithmus funktioniert analog dem
Broadcast-Multiply-Roll Algorithmus (Alg. 4.4)
im nächsten Abschnitt.
Gundolf Haase
1998-12-22