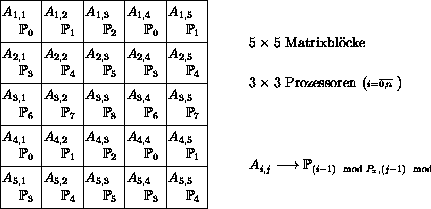Next: 6.3 Gaußelimination für tridiagonale
Up: 6.2 Die LU-Zerlegung
Previous: 6.2.1 Vektorisierung der LU-Zerlegung
6.2.2 Parallelisierung der LU-Zerlegung
Im folgenden nehmen wir einen Parallelrechner mit
verteiltem Speicher an.
Zur Vorbereitung der Parallelisierung benötigen wir einen anderen
Algorithmus der LU-Zerlegung, wobei diesmal 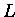 spaltenweise, und
spaltenweise, und
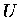 zeilenweise gespeichert sein soll. Eine Pivotisierung wird nicht
betrachtet.
zeilenweise gespeichert sein soll. Eine Pivotisierung wird nicht
betrachtet.
![\begin{algorithmus}% latex2html id marker 27037
[H]\caption{Rang-r-Modifikation ...
...ace \\
\>\> END DO \\
\> END DO \\
\par END DO
\end{tabbing}\end{algorithmus}](img723.gif)
Abbildung 6.4:
Illustration zur Rang-r-Modifikation
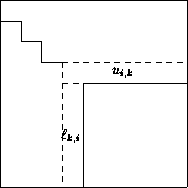 |
Zum Zwecke der Parallelisierung bietet sich die Blockvariante der
Rang-r-Modifikation an. Hier bezeichnet 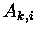 die Zeilen und
Spalten der Blockaufteilung der Matrix
die Zeilen und
Spalten der Blockaufteilung der Matrix  .
.
![\begin{algorithmus}% latex2html id marker 27094
\caption{Blockvariante der Rang-...
...erline{i+1,n} \makebox[0pt]{})$\space \\
END DO
\end{tabbing}\end{algorithmus}](img726.gif)
Bei einer zeilen- bzw. spaltenweisen Aufteilung der Matrix
werden desto weniger der verfügbaren Prozessoren eingesetzt je kleiner
die Restmatrix wird (siehe Bild 6.4).
Gestreute Aufteilung von quadratischen Blockmatrizen
(square block scattered decomposition), wie sie
in der parallelisierten Version von ScaLAPACK benutzt wird.
Bsp.: Gestreute Aufteilung
-
-
Mittels der gestreuten Aufteilung der Matrix
kann nun die
Parallelisierung der Blockvariante aufgeschrieben werden.
![\begin{algorithmus}% latex2html id marker 27200
\caption{Blockweise Rang-r-Modif...
...ot U_{i,\ell}$\space \\
END DO
\end{tabbing}\mbox{}\\ [-5ex]
\end{algorithmus}](img728.gif)
Bemerkung :
Vom Standpunkt der Implementierung empfiehlt sich hier eine nichtblockierende
Kommunikation.
In Richtung der Spalten und Zeilen ist auch eine Verteilung analog der
Hypercubenumerierung denkbar.
Next: 6.3 Gaußelimination für tridiagonale
Up: 6.2 Die LU-Zerlegung
Previous: 6.2.1 Vektorisierung der LU-Zerlegung
Gundolf Haase
1998-12-22