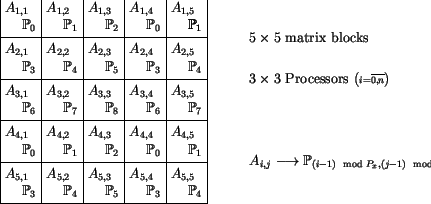Next: 6.3 Gauß elimination of
Up: 6.2 LU factorization
Previous: 6.2.1 Vectorization of LU
Contents
6.2.2 Parallelization of the LU factorization
In the following we have a distributed memory computer in mind.
Here, we investigate another algorithm for the LU factorization without
Pivot search. Again, 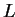 is stored column-wise and
is stored column-wise and 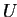 is stored
rowise.
is stored
rowise.
![\begin{algorithmus}
% latex2html id marker 26997
[H]\caption{Rank-r-modification...
..._{i,j}$\ \\
\>\> END DO \\
\> END DO \\
END DO
\end{tabbing}\end{algorithmus}](img750.gif)
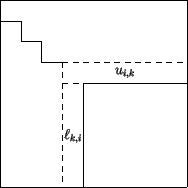
Figure 6.4:
Illustration to the rang-r-modification
 |
For the purpose of parallelization, a block variant of the
rank-r-modification seems preferable.
Now, 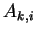 denotes the rows and columns of the block splitting
of matrix
denotes the rows and columns of the block splitting
of matrix 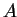 .
.
![\begin{algorithmus}
% latex2html id marker 27054
\caption{Block variant of rank-...
...l=\overline{i+1,n} \makebox[0pt]{})$\ \\
END DO
\end{tabbing}\end{algorithmus}](img753.gif)
If one uses a rowise or column-wise distribution of matrix
on the processors, then the smaller the rest matrix gets the fewer
processors are used (see Fig. 6.4).
square block scattered decomposition as it is used in a parallel
version of ScaLAPACK.
Ex.: Scattered distribution
-
Now we can formulate the parallel block version by using the
scattered distribution of .
![\begin{algorithmus}
% latex2html id marker 27159
[H]
\caption{Block wise rank-r-...
...i}\cdot U_{i,\ell}$\ \\
END DO
\end{tabbing}\mbox{}\\ [-5ex]
\end{algorithmus}](img755.gif)
Remark :
A non-blocking communication seems advantageous from the
point of implementation .
A distribution of blocks in direction of rows and columns
similar to the hypercube numbering (ring embedded in hypercube !) is also possible.
Next: 6.3 Gauß elimination of
Up: 6.2 LU factorization
Previous: 6.2.1 Vectorization of LU
Contents
Gundolf Haase
2000-03-20