


Next: 5.5.3 Die parallele IUL-Faktorisierung
Up: 5.5 Unvollständige Zerlegungen
Previous: 5.5.1 Der serielle Algorithmus
5.5.2 Die parallele ILU-Faktorisierung
Die erste Idee zur Parallelisierung der ILU ist die einfache Übertragung von
Algorithmus 5.12 auf eine akkumulierte Matrix
 .
Natürlicherweise sind
.
Natürlicherweise sind
 und
und
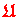 ebenfalls akkumuliert.
Jedoch müssen nun wegen (4.9) und (4.10)
die Forderungen 3a und 3b an die Vernetzung
aus Abschnitt 4.3.1 erfüllt sein.
ebenfalls akkumuliert.
Jedoch müssen nun wegen (4.9) und (4.10)
die Forderungen 3a und 3b an die Vernetzung
aus Abschnitt 4.3.1 erfüllt sein.
![\begin{algorithmus}% latex2html id marker 20055
[H]\caption{Parallelisierte $\pr...
...space &
DD $\rightarrow$\space block matrices
\end{tabular}
\end{algorithmus}](img578.gif)
Da die redundant gespeicherten Matrizen
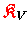 ,
,
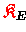 ,
,
,
,
 und
und
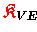 nach der Akkumulation bis zur Zerlegung nicht mehr modifiziert werden,
kann die Akkumulation vor der Faktorisierung ausgeführt werden.
nach der Akkumulation bis zur Zerlegung nicht mehr modifiziert werden,
kann die Akkumulation vor der Faktorisierung ausgeführt werden.
In 3D kommt noch ein Block mit den Faces ''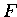 '' hinzu.
Die entsprechende Faktorisierung ist analog, jedoch müssen
an die Vernetzung weitere Forderungen gestellt werden.
'' hinzu.
Die entsprechende Faktorisierung ist analog, jedoch müssen
an die Vernetzung weitere Forderungen gestellt werden.
Betrachtet man den Auflösungsschritt
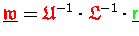 näher und trägt den mit akkumulierten Matrizen erlaubten
Matrix-Vektor-Multiplikationen (4.9) und (4.10)
Rechnung, so sieht man aus Gleichung (4.13a),
daß 3 Vektortypumwandlungen auftreten müssen.
näher und trägt den mit akkumulierten Matrizen erlaubten
Matrix-Vektor-Multiplikationen (4.9) und (4.10)
Rechnung, so sieht man aus Gleichung (4.13a),
daß 3 Vektortypumwandlungen auftreten müssen.
![\begin{algorithmus}% latex2html id marker 20205
[H]\caption{Paralleler Aufl\uml ...
...suremath{\color{green} {\sf w}} }}_i$\space \\
\end{tabular}
\end{algorithmus}](img583.gif)
Die Diagonalmatrix 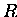 mit der Anzahl der am Knoten anliegenden
Teilgebiete wurde in (4.4) definiert.
mit der Anzahl der am Knoten anliegenden
Teilgebiete wurde in (4.4) definiert.
Verbesserung :
Der Nachteil von Algorithmus 5.15 besteht vor allem darin, daß
jeweils gerade ein anderer als der gegebene Vektortyp benötigt wird.
Dadurch sind 3 Vektortypumwandlungen mit 2 Akkumulationsschritten notwendig.
Dies bedeutet in einem Iterationsverfahren mit der 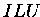 als
Vorkonditionierer doppelten Kommunikationsaufwand gegenüber
dem
als
Vorkonditionierer doppelten Kommunikationsaufwand gegenüber
dem 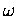 -Jacobi-Verfahren.
-Jacobi-Verfahren.
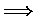 Ein Auflösungsschritt
Ein Auflösungsschritt
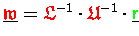 würde
laut (4.12a) nur eine Vektortypumwandlung mit einer
Akkumulation benötigen.
würde
laut (4.12a) nur eine Vektortypumwandlung mit einer
Akkumulation benötigen.
Next: 5.5.3 Die parallele IUL-Faktorisierung
Up: 5.5 Unvollständige Zerlegungen
Previous: 5.5.1 Der serielle Algorithmus
Gundolf Haase
1998-12-22