Im Jahre 1966 unterschied Michael Flynn [Fly66]
parallele Architekturen bzgl. des Datenstroms
und des Stromes der Programmanweisungen, so daß sich 4 Formen
der Parallelität ergeben.
nur prozessorinterne Parallelität (bitparallel, look-ahead)
Pseudeoparallelität mittels Multitasking und Time-Sharing
(Durchsatzerhöhung der Anlage)
SIMD :
Parallelität auf Anweisungsebene
1.
Die Daten sind über die Prozessoren verteilt, ein
Programm wird ''im Gleichschritt'' auf allen Prozessoren abgearbeitet.
Meist sehr einfache, dafür aber viele
Prozessoren (Prozessorfelder CM2, MasPar).
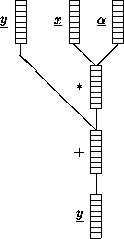
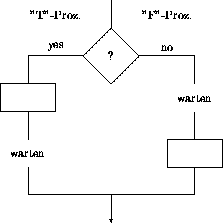
Ein typisches Problem bei SIMD sind Programmalternativen :
Liefert der Test ''?'' bei 2 Prozessen der SIMD-Maschine
unterschiedliche Ergebnisse (T/F),
ändert sich das Struktogramm in
,d.h. eigentlich läuft ab :
2.
Der Vektorrechner
benutzt das Pipelining derart, daß im Unterschied
zum skalaren Rechner die gleiche Befehlssequenzen mit Datensätzen
wiederholt werden. Eine typische Operation ist die
SAXPY-Operation
in Abb. 2.1,
welche auf einen Vektor
den mit der reellen Zahl
skalierten Vektor
addiert. Die Pipeline besteht in diesem
Falle aus Addition, Multiplikation, Lade- und Speicheroperationen
welche mit den Vektorregistern durchgeführt werden.
Nach einem ''Startup'' wird i.a. pro Taktzyklus ein Ergebnis
geliefert, obwohl in der skalaren Rechnung mehr Takte notwendig sind.
Abbildung 2.1:
SAXPY im Vektorrechner
Um hohe MFLOP-Raten zu erreichen, müssen die Vektorregister stets
gefüllt sein ! Bei Nichtbeachtung dieser Forderung ist der Einsatz
des Vektorrechners sinnlos, da nur die skalare Rechenleistung
erreicht wird. In nebenstehender Abbildung tritt ein
Vektor
auf, welcher nichts anderes als das Auffüllen
des entsprechenden Vektorregisters mit dem Skalar
symbolisiert.
Dies wird automatisch vom Compiler getan, da der Vektorrechner eigentlich
nur die Operation
effizient behandeln kann.
Aus der Sicht des Mathematikers im Sinne der Parallelisierung mathematischer
Algorithmen beschleunigt der Vektorrechner ''nur'' die sequentiellen
Algorithmen ohne etwas an ihnen zu ändern.
MIMD :
Bedeutet Parallelität auf Programmebene, d.h. jeder Prozessor
arbeitet sein eigenes Programm ab. Dies geschieht in der Regel aber
nicht unabhängig voneinander, daher unterscheidet man :
Unterscheide
Programm (statisch) :
Exakte Niederschrift eines Algorithmus
Prozeß (dynamisch) :
Folge von Aktionen, einzige Annahme: positive
Geschwindigkeit.
Oft repräsentiert jeder Prozeß dasselbe Programm, allerdings
mit unterschiedlichen Daten.
SPMD als Unterklasse der MIMD
SPMD :
Single Program Multiple Data
Wird auf größeren Parallelrechnersystemen und vor allem bei
massiv parallelen Rechnern verwendet.
Datenparallelität muß vorhanden sein.
Kein SIMD, da kein Gleichschritt in Anweisungsebene
erforderlich. Jedoch müssen im Normalfall in den
Synchronisationszeitpunkten Daten angeglichen werden.
![\begin{figure}
\begin{center}
\unitlength0.05\textwidth
\begin{picture}
(8,6)
...
...b]{yes}} \put(6,4.2){\makebox(0,0)[b]{no}}
\end{picture}\end{center}\end{figure}](img47.gif)
![\begin{figure}
\unitlength0.08\textwidth
\begin{picture}
(9,12)
\put(0,7){\li...
...ector(0,-1){11}} \put(9.2,0.5){\makebox(0,0)[l]{t}}
\end{picture}
\end{figure}](img49.gif)
![\begin{figure}[H]
\unitlength0.03\textwidth
\mbox{}\hfill
%%\begin{picture}(5,1...
...ng der Schwie\-rig\-kei\-ten)
\end{minipage}\hfill\mbox{}\\ [1ex]
%
\end{figure}](img59.gif)