Next: 3.2 Synchronisation paralleler Prozesse
Up: 3. Parallelität auf algorithmischer
Previous: 3. Parallelität auf algorithmischer
3.1 Einige Begriffe
Skalierbarkeit :
Einfache Anpassung eines Programmes an eine real verfügbare Anzahl von
Prozessoren.
Skalierbarkeit wird mittlerweile höher bewertet als höchste Effizienz
(d.h. Gewinn an Rechenzeit durch Parallelisierung) auf einer speziellen
Architektur.
Granularität :
Größe der Programmabschnitte, welche ohne Kommunikation mit anderen
Prozessoren ausführbar sind.
Feinkörniger Algorithmus :
 Systolische Felder [SIMD]
Systolische Felder [SIMD]
Bsp.:  -Jacobi-Iteration
-Jacobi-Iteration
-
- Laplace-Problem, mit dem 5-Punkte-Differenzenstern diskretisiert.
Hier treten keinerlei Datenabhängigkeiten innerhalb einer Iteration auf.
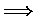 Gut parallelisierbar (und vektorisierbar).
Gut parallelisierbar (und vektorisierbar).
Bsp.: -Gauß-Seidel-Iteration (vorwärts)
-
- Laplace-Problem, mit dem 5-Punkte-Differenzenstern diskretisiert.
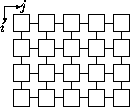
Abbildung 3.1:
Gauß-Seidel im systolischen Feld
 |
Die Werte
![$\widehat{c} \makebox[0pt]{}_{i-1,j}$](img130.gif) und
und
![$\widehat{c} \makebox[0pt]{}_{i,j-1}$](img131.gif) müssen berechnet sein,
bevor
müssen berechnet sein,
bevor
![$\widehat{c} \makebox[0pt]{}_{i,j}$](img132.gif) berechnet werden kann.
berechnet werden kann.
- Berechnung als Wellenfront {1,2,3,4-ter Schritt}.
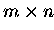 systolisches Feld
systolisches Feld
(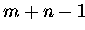 )
Zeitschritte für eine Iteration
nötig.
)
Zeitschritte für eine Iteration
nötig.
mehrere Iterationen kompensieren diesen Overhead
beim Startup.
1. Iteration :
Zeitgewinn :
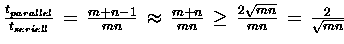
Ideal wäre aber ein Verhältnis
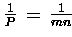 !
!
2. Iteration :
- Nach Initialisierung benötigt eine Iteration nur noch
einen Zeitschritt.
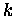 -te (letzte) Iteration benötigt gleiche Zeit wie Initialisierung
-te (letzte) Iteration benötigt gleiche Zeit wie Initialisierung
Asymptotisch, d.h. bei vielen Iterationen wird der bestmögliche
Zeitgewinn durch die Parallelisierung erzielt.
Grobkörniger Algorithmus :
Mehrprozessorrechner [MIMD]
z.B. Blockvarianten von -Jacobi- bzw. Gauß-Seidel-Iteration
Bemerkung : Heutzutage ist der Zeitbedarf für eine Kommunikation zwischen den
Knoten/Prozessoren deutlich höher als für lokalen Speicherzugriff
bzw. arithmetische Operationen. Daher sind
grobkörnige Algorithmen für die Parallelisierung gefragt.
Funktionale Parallelität :
Aufspaltung eines Algorithmus in funktional unterschiedliche,
parallel abarbeitbare Teilschritte.
Bsp.:
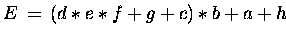
- seriell (von links nach rechts) 7 Zeitschritte
- parallel 2 Prozessoren 5 Zeitschritte
Abbildung 3.2:
Funktionale Parallelität
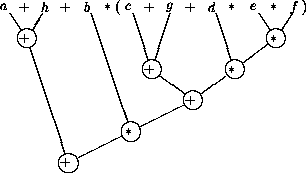 |
Aufgabe :
Teilen Sie obige Berechnungsvorschrift auf 3 Prozessoren auf.
Nutzen Sie Umformungsregeln. (Ergebnis: 4 Zeitschritte)
- Im parallelen Fall können in Summe mehr arithmetische Operationen
auftreten, trotzdem ist die parallele Variante (theoretisch) schneller.
- Funktionale Parallelität ist nur bedingt skalierbar. In obigem
Beispiel ergeben mehr als 3 Prozessoren keine weitere Zeitersparnis.
Datenparallelität :
Gleiche Programmabschnitte werden parallel über verschiedenen
Datensegmenten ausgeführt.
- Voraussetzung: Einfache Aufteilung der Daten in Segmente
(High Performance Fortran).
- (relativ) leicht skalierbar. Probleme treten bei komplexen
Datenzusammenhängen auf, z.B.
bei indirekter Adressierung (FEM).
Bsp.: Block--Jacobi
-
- Aufteilung der Vektoren und (Block-)Matrizen.
- Mehrere Möglichkeiten der Datenaufteilung (siehe Abschnitt 5)
Spezialfall : Geometrische Parallelität.
Die Aufspaltung der Daten in Teilmengen entsprechend geometrischer
Überlegungen über der räumlichen Anordnung der Objekte
(Teilchen, Diskretisierungspunkte etc.), bzw. Ausnutzung von
Nachbarschaftsbeziehungen bei Diskretisierungsmethoden wie FEM, FDM, FVM.
Next: 3.2 Synchronisation paralleler Prozesse
Up: 3. Parallelität auf algorithmischer
Previous: 3. Parallelität auf algorithmischer
Gundolf Haase
1998-12-22