


Nächste Seite: 1.3.5 Lokaler Datenaustausch
Aufwärts: 1.3 Die Praktikumsaufgaben
Vorherige Seite: 1.3.3 Blockierende Kommunikation
Der Double-Precision-Vektor
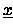 sei blockweise disjunkt verteilt, d.h.,
verteilt über alle Prozesse s
(
s =
sei blockweise disjunkt verteilt, d.h.,
verteilt über alle Prozesse s
(
s = 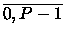 ), daß
= (
), daß
= (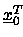 ,...,
,...,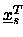 )T gilt.
)T gilt.
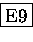
- Schreibe eine Funktion
DebugD(nin,xin,icomm)
welche nin Double-Precision-Zahlen des Vektors xin auf dem
Bildschirm ausgibt.
Starte das Programm mit mehreren Prozessen.
 Alle Prozesse schreiben durcheinander ihre lokalen Vektoren
aus, d.h., eine Fehlersuche wird sehr erschwert.
Alle Prozesse schreiben durcheinander ihre lokalen Vektoren
aus, d.h., eine Fehlersuche wird sehr erschwert.
Verbessere die Funktion DebugD derart, daß Prozeß 0
vom Terminal die Nummer des Prozesses einliest, welcher Daten ausgeben soll.
Nutze
um diese Information allen Prozessen mitzuteilen, sodaß diese
entsprechend reagieren können.
Evtl. muß MPI_Barrier benutzt werde, um die Ausgabe
zu synchronisieren.

- Vertausche das globale Minimum und Maximum des Vektors
!
Benutze hierbei die Funktionen
Wie kann man den Kommunikationsaufwand reduzieren?
Hinweis :
Berechne zuerst die lokalen Minima und Maxima und laß danach einen
Prozeß die globalen Größen bestimmen.
Man kann alternativ auch gleich die Funktion
MPI_Allreduce
mit den Operationen
MPI_Minloc/ MPI_Maxloc
benutzen.

- Schreibe eine Funktion, welches das globale Skalarprodukt
Skalar(n,x,y,icomm)
zweier Double-Precision-Vektoren x und y
der lokalen Länge n berechnet. Benutze
Nächste Seite: 1.3.5 Lokaler Datenaustausch
Aufwärts: 1.3 Die Praktikumsaufgaben
Vorherige Seite: 1.3.3 Blockierende Kommunikation
Gundolf Haase
1999-10-04