

Next: 5 Local data exchange
Up: Course on Parallelization
Previous: 3 Synchronized Communication
Let some Double Precision vector
 be stored blockwise disjoint, i.e., distributed over all processes s
(
s = 0,..., P - 1) such that
= (
be stored blockwise disjoint, i.e., distributed over all processes s
(
s = 0,..., P - 1) such that
= ( ,...,
,...,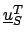 )T.
)T.
-
- Write a routine
DebugD(nin,xin,icomm)
that prints nin Double Precision numbers of the array xin.
Start the program with several processes.
 All processes will write their local vectors, i.e.,
one has to look carefully for the data of process s.
All processes will write their local vectors, i.e.,
one has to look carefully for the data of process s.
Improve the routine DebugD such that process 0 reads
the number (from terminal) of that process which is to write
it's vector. Use
to broadcast this information and let the processes react appropriately.
If necessary use
MPI_Barrier
to synchronize the output.
-

- Exchange global minimum and maximum of the vector
!
Use
How can you reduce the amount communication ?
Hint:
Compute, first, local min./max. and afterwards let some process
determine the global quantities.
Alternatively, you can use
MPI_Allreduce
and the
operations
MPI_Minloc/MPI_Maxloc.
-

- Write a routine for computing the global scalar product
Skalar(n,x,y,icomm)
of two Double Precision vectors x and y
of local length n. Use
Next: 5 Local data exchange
Up: Course on Parallelization
Previous: 3 Synchronized Communication
Gundolf Haase
2003-05-19