| |
CUBE/SMALL>_DO |
| TREE/SMALL>_DO |
 |
equivalent arithmetical costs |
|
|
nCube bi-directional communications or
2 nCube uni-directional communications nCube uni-directional communications |
| 2nCube uni-directional communications |
|
same bandwidth on all links required |
| decreasing bandwith required with increasing/decreasing
link number |
|
best choice if all links have the same bandwidth
Ideal bei gleicher Bandbreite aller Links |
| Selection of the tree embedded in the hypercube
with respect to the bandwidth of the links |
|
best in a physical hypercube, e,g, NCUBE2 |
| With larger systems technologically caused smaller bandwidths
can occur on some links, e.g., POWER-GC |
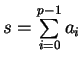 ).
At the end, the result is available on one root process
(Reduce operation) or on all processes (All-Reduce).
).
At the end, the result is available on one root process
(Reduce operation) or on all processes (All-Reduce).
![$ s_0 := [(a_0+a_4)+(a_2+a_6)] + [(a_1+a_5) + (a_3+a_7)]
= \sum\limits_{i=0}^{p-1} a_i$](img201.gif)
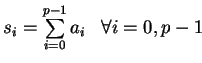

![\begin{figure}\unitlength0.04\textwidth
\begin{center}
\begin{picture}(14,9)(0...
...5}} \put(5.9,8.4){\makebox(0,0)[bl]{c)}}
\end{picture} \end{center} \end{figure}](img193.gif)
![\begin{figure}\unitlength0.04\textwidth
\begin{center}
\begin{picture}(11,11)
...
...akebox(0,0)[br]{$\scriptstyle a)$}}
%
\par\end{picture}\end{center}\end{figure}](img207.gif)