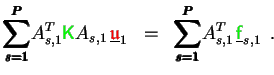The main problem in parallelizing a (multilevel or) multigrid algorithm
consists in solving the coarse grid system exactly.
(5.10)
The following ideas are common :
Direct solver - sequential
The coarsest grid is so small that one processor
can
store it additionally.
Accumulate
(REDUCE).
Accumulate
(REDUCE).
Processor
solves
.
Distribute
to all other processors (SCATTER).
This algorithm is purely sequential !
Direct solver - parallel
We store parts of the accumulated matrix on all processors
and solve the coarse grid system by some direct parallel
solver. Therein, load inbalancies will appear.
Iterative solver - parallel
Here, no accumulation of
and
is
necessary but in each iteration at least one
accumulation has to be performed
(see 5.1 - 5.6).
Caution : If cg-like methods are used as coarse grid solvers
then a symmetric multigrid operator cannot be achieved.
To preserve the symmetry one should combine, e.g., a
Gauß-Seidel forward iteration with the appropriate
backward iteration (SSOR).
The (usually poor) ratio between communication and arithmetic
behavior of parallel machines results in a bad parallel
efficiency of the coarse grid solver.
This can be observed if one uses a W-cycle on 32 or more processors
because that multigrid cycle works on the coarser grids more
often then a V-cycle.
One idea to overcome this bottleneck consists in the distribution of
the coarse (or the coarser) grid on less then processors.
The disadvantage of this approach is the appearance of communication
between certain grids and
in the
intergrid transfer.