| |
CUBE/SMALL>_DO | TREE/SMALL>_DO |
 |
Gleicher arithmetischer Aufwand |
|
|
nCube bidirektionale Kommunikationen oder
2 nCube unidirektionale Kommunikationen nCube unidirektionale Kommunikationen | 2 nCube unidirektionale Kommunikationen |
|
Gleiche Linkbelastung | Sinkende Linkbelastung mit wachsender/fallender Linknummer |
|
Ideal bei gleicher Bandbreite aller Links | Auswahl des im Hypercube eingebetteten Baumes nach der
Bandbreite der Links |
|
Ideal im physischen Hypercube, z.B. NCUBE2 | Bei größeren Systemen können technologisch bedingte
geringere Bandbreiten bei einigen Links auftreten, siehe
Bsp. POWER-GC |
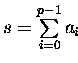 ).
Das Ergebnis steht am
Ende einem Root-Prozeß (bei Reduce) bzw. allen Prozessen
(bei All-Reduce) zur Verfügung.
).
Das Ergebnis steht am
Ende einem Root-Prozeß (bei Reduce) bzw. allen Prozessen
(bei All-Reduce) zur Verfügung.
![$s_0 := [(a_0+a_4)+(a_2+a_6)]\,+\,[(a_1+a_5)\,+\,(a_3+a_7)]
\,=\, \sum\limits_{i=0}^{p-1} a_i$](img195.gif)
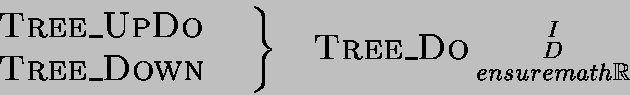
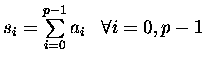
![\begin{figure}
\unitlength0.04\textwidth
\begin{center}
\begin{picture}
(14,9...
...}} \put(5.9,8.4){\makebox(0,0)[bl]{c)}}
\end{picture} \end{center}
\end{figure}](img187.gif)
![\begin{figure}
\unitlength0.04\textwidth
\begin{center}
\begin{picture}
(11,1...
...\makebox(0,0)[br]{$\scriptstyle a)$ }}
%
\end{picture}\end{center}
\end{figure}](img201.gif)